|
SST/macro
|
Just as jobs must be launched on a shared supercomputer using Slurm or aprun, SST/macro requires the user to specify a launch command for the application. Currently, we encourage the user to use aprun from Cray, for which documentation can easily be found online. In the parameter file you specify, e.g.
which launches an external user C++ application with eight ranks and two ranks per node. The aprun command has many command line options (see online documentation), some of which may be supported in future versions of SST/macro. In particular, we are in the process of adding support for thread affinity, OpenMP thread allocation, and NUMA containment flags. Most flags, if included, will simply be ignored.
In order for a job to launch, it must first allocate nodes to run on. Here we choose a simple 2D torus
which has 9 nodes arranged in a 3x3 mesh. For the launch command aprun -n 8 -N 2, we must allocate 4 compute nodes from the pool of 9. Our first option is to specify the first available allocation scheme (Figure 8)

Figure 8: First available Allocation of 4 Compute Codes on a 3x3 2D Torus
In first available, the allocator simply loops through the list of available nodes as they are numbered by the topology object. In the case of a 2D torus, the topology numbers by looping through columns in a row. In general, first available will give a contiguous allocation, but it won't necessarily be ideally structured.
To give more structure to the allocation, a Cartesian allocator can be used (Figure 9).

Figure 9: Cartesian Allocation of 4 Compute Codes on a 3x3 2D Torus
Rather than just looping through the list of available nodes, we explicitly allocate a 2x2 block from the torus. If testing how "topology agnostic'' your application is, you can also choose a random allocation.

Figure 10: Random Allocation of 4 Compute Codes on a 3x3 2D Torus
In many use cases, the number of allocated nodes equals the total number of nodes in the machine. In this case, all allocation strategies allocate the same set of nodes, i.e. the whole machine. However, results may still differ slightly since the allocation strategies still assign an initial numbering of the node, which means a random allocation will give different results from Cartesian and first available.
Once nodes are allocated, the MPI ranks (or equivalent) must be assigned to physical nodes, i.e. indexed. The simplest strategies are block and round-robin. If only running one MPI rank per node, the two strategies are equivalent, indexing MPI ranks in the order received from the allocation list. If running multiple MPI ranks per node, block indexing tries to keep consecutive MPI ranks on the same node (Figure 11).
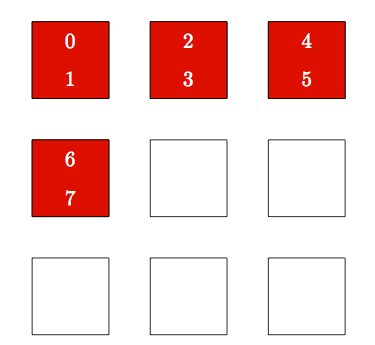
Figure 11: Block Indexing of 8 MPI Ranks on 4 Compute Nodes
In contrast, round-robin spreads out MPI ranks by assigning consecutive MPI ranks on different nodes (Figure 12).
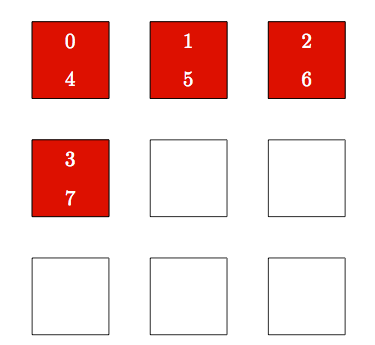
Figure 12: Round-Robin Indexing of 8 MPI Ranks on 4 Compute Nodes
Finally, one may also choose
Random allocation with random indexing is somewhat redundant. Random allocation with block indexing is not similar to Cartesian allocation with random indexing. Random indexing on a Cartesian allocation still gives a contiguous block of nodes, even if consecutive MPI ranks are scattered around. A random allocation (unless allocating the whole machine) will not give a contiguous set of nodes.
 1.8.11
1.8.11

